日志
最火人工智能技术科普--你只需要注意力
热度 1 ||
前些时候看到一段泽连斯基的乌克兰语演讲视频,但没有字幕,不知道他在说什么。而那时正好有一款称为 Whisper 的开源软件 https://openai.com/blog/whisper/,用人工智能技术能够将语音录写成文字,还能进行翻译,支持几十种语言。我于是下载了 Whisper,对视频里的讲话进行了翻译。另外我找了一首邓紫棋的歌,唱的虽然是普通话,但我大部分听不明白,Whisper 竟然非常准确的听出来了。我又找了首歌词含糊的英文歌进行了测试,也高分通过。这是什么技术?
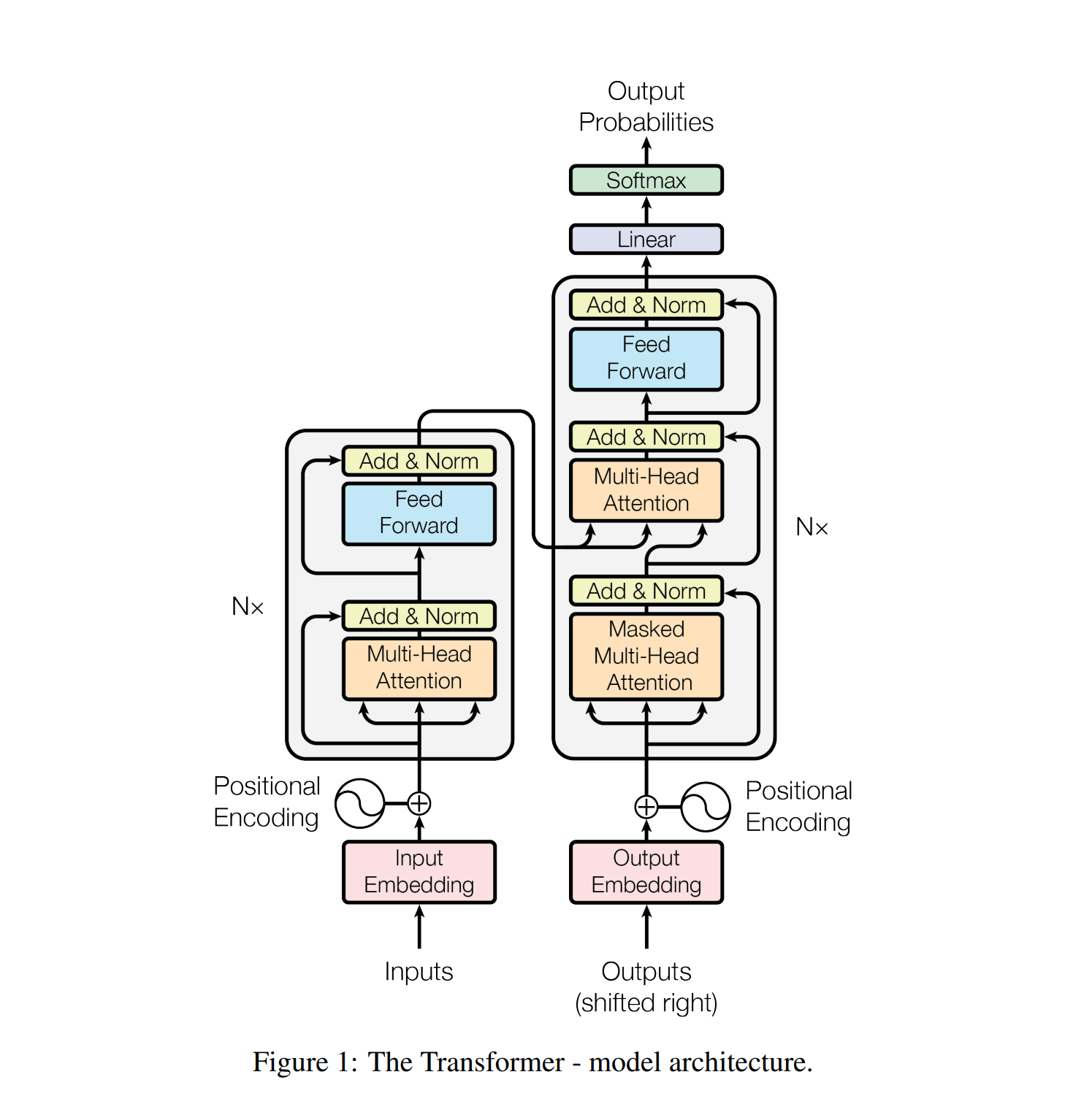
查看其技术说明之后,发现它就是用了一个转换器(Transformer) 的人工神经网络,用大量的语音--文字进行训练而成。那么什么是 Transformer 呢?这是2017年一篇论文中提出来的一种人工智能构架,论文的标题是 Attention is All You Need (你需要的全部就是注意力)。这个标题就很牛,似乎是万能钥匙。眼见为实。Whisper 几乎是一个原封的 Transformer -- 只是输入的是语音序列, 就能展现如此强大的实用功能,能翻译几十种语言,再不学习就要永远落后了。
于是我在网上查阅各种资料,试图弄清楚这个 Transformer 的算法与原理。其中哈佛大学一个小组将论文用 PyTorch 实现并进行了相当详细的注解。但还是有很多地方不很明白。最后,我决定用自己讲述的方式把这个过程写下来,这也是学习的最佳方式之一。
先说什么是人工智能。所有的计算都可以看成一个黑盒子,输入一些东西,输出一些结果。人工智能的方法是,构造一个具有很多可调参数的函数,然后通过所谓训练去调节这些参数的数值,直到函数能够输出比较正确的结果。令输入为 x,输出为 y ,参数为W。可以用下面的公式表达。
$y = F(x, W)$
以中译英翻译为例,输入一行中文 x, 我们期待输出对应的英语句子。人工智能的方法是构建函数F,这个函数有很多参数 W。通过用很多已知的中-英对照对F进行训练,不断调整参数W,直到它能够完成翻译任务。从某种意义上,这跟婴儿学说话差不多。婴儿学说话,并不需要学会语法之类,跟着大人说,说错了就被纠正,慢慢就会了。学语法、修辞那是上学后的事。
这是一个很高的视角,任何知识都可以用 y=F(x) 表示,具体的这个函数 F 怎么构造就是运用之妙、存乎一心了。下面我讲讲 Transformer 是怎么工作的。
Transformer 有一个输入口,一个输出口。输入是一次性的,以中译英翻译为例,如果需要翻译的句子是 “我在看书”,这四个中文词被一次性输入。这四个中文词被输入后,在 Transformer 内部进行一系列运算,转换成另外一组数据,比如说是一种未知的宇宙语言的表达。这个过程在 Transformer 中叫着编码,这部分的神经网络叫着编码器 (Encoder)。编码器完成编码后,其产生的数据被转到下一个部分,称为解码器 (Decoder)。解码器的任务是输出我们需要的的结果。解码器除了得到从编码器传来的数据,还有一个内部输入口,这个内部输入是之前已经输出的数据。Transformer 输入是一次性的,但输出却是一个词一个词的进行,每输出一个词,这个词就被送到 Decoder 的输入口,作为下一轮的输入。以 “我在看书”翻译成英语为例,Transformer 的编码器一次性接受了这个四个中文字。然后解码器输出英文 I,这个I 又被输入到解码器,解码器结合编码器提供的数据以及这个已经输出的I,继续输出下一个词,可能是 "am",如此反复,最后期待的结果是 “I am reading a book”。最初,我们的人工智能对中英文一无所知,输出的应该都是毫无意义的东西,但经过深度学习,不断调整参数之后,如果我们的 F 构造巧妙,也许经过一段时间的训练之后,能较快的掌握中译英技巧。而如果构造不行,可能再怎么训练也无济于事。Transformer 的长处正是其能够以较快的速度完成训练任务。智力判断的主要标准是学习的速度。而 Transformer 这个智商的来源是所谓“注意力”,英文是 Attention.
Attention 又是一个通过机器学习确定的神经网络函数,它的功能计算输入句子中不同的词之间的关联度。在语言处理中,一个词用一个向量表达。Attention 输入三串向量 x, y, z, 输出一串向量。在 Transformer 的编码器一端,输入的三串向量都是相同的,就是输入的句子(词序列),但在 Transformer 的解码器的中间,三串中一串是解码器生成的序列,另外两串则是编码器先前生成的序列。
Attention 内部有三个通过机器学习确定的线性算符,称为 Q, K,V (Query,Key, Value)。它们的作用是将输入投射到一个子空间 。下面的公式中,下标为空间坐标,上标为序列位置指数,希腊字母为子空间坐标指数,从1到d,i,j,l 为输入向量空间指数,从1到D,a 为 x 输入序列的指数,从1 到 n; b 为 y 与 z 序列的指数,从 1到 m。以句子x为例,[ix]x^2_3[/ix]表示第二个词的向量表达的第三个分量。 如果使用矩阵 表示,Q、K、V的都是 D x d 维的矩阵。分量表达为(重复下标求和):
$q_{\mu} ^{a} = Q_{\mu i}x_i^{a}\\
k_{\mu}^{b} = K_{\mu j} y_j^{b} \\
v_{\nu}^{b} = V_{\nu l} z_l^{b}\\
$
q 与 k,v 的上标不同,这是因为 两者的长度可以是不一样的。上面的运算只是将输入的单个向量(也就是单个单词)从D维空间投射到一个d维空间,尚未产生不同向量(不同词)之间的关联。下一步,我们将 q 与 k "缩并",得出 S
$S^{a b} = q_{\mu} ^{a} k_{\mu}^{b}$
具体的算法中,还会将 S 除以 d 的平方根,然后用所谓 softmax 函数 进行调整,类似于将每一行的值视为一个能量分布,计算各自的分布几率(负温度)。因此S将不再是线性。这里就不写了。
得到这个 S 之后,下一步就是计算注意力 A,
$A^{a}_{\nu} (x, y, z) = S^{a b} v^{b}_{\nu} $
可见,A 包含了 y, z 序列中不同的词对 x 序列的影响。同时也可以看出,这个影响与词在句子里的位置无关,因此即使在输入序列中相距很远的词也能够产生关联,而不是距离太远就关联变小,这个长程相干性是 Attention 机制的一个很大的优势。一句话里,可能两个相距很远的词却密切相关,Attention 能够保留这种关联。但是,我们当然知道一个词在句子中的顺序位置也是重要的,词的位置信息应该加以保留。对此,论文中的解决方法是在输入编码上加一个位置相关的向量。
另外,由上面的公式看出,A 是 n x d 矩阵。输入的 x 序列长度为 n, 但每一个向量的维数为 D,因此无法直接将 A 加到输入序列 x 之上。解决方案是,设置 D/d 个注意力头,然后把它们的结果拼接起来。这样维数就与输入对上了,可以直接相加了。这叫多头注意力 (Multihead Attention)。
在编码器一端,基本的函数表达就是 x = x + A(x,x,x) ,然后输入一个标准的网络,并重复多层。三个输入都是 x,这叫做 自注意力(self-attention)。另外,不要小看了这个 x + A(x)。这叫剩余网络 (ResNet),相关论文可能是人工智能领域被引用次数最多的。
在解码器一端,基本的函数表达是
y(t+1) = y(t) + A(y, X, X)
并重复多层。其中 X 是编码器计算出来对输入序列的表达,而 y 则是已经得到的输出结果。这叫交叉注意力。具体到中译英,相当于先得出一个基于自注意力的中文输入的数学表达,然后用这个表达与已经输出的英文单词结合,推出下一个英文单词,如此不断迭代。至于为什么上面这一个套路能够很好的工作,并没有谁给出一个基于数理逻辑的证明。就像谷歌的人士看不懂阿法狗下围棋的思路一样。人工智能的方法是给足够的灵活性、关联性,让计算机自己去调整学习。
Transformer 的一个优势是,其在进行训练时,它不需要进行迭代,而可以巧妙的用一个 mask,做并行处理。这就是细节了。
写完这篇博文,已经是基本清楚了。对比目前网上的各种介绍文章,上面对于关键细节可能讲得更清楚。







